[발번역] Apache Kafka를 사용한 컨슈머 재시도 설계 - Retrying consumer architecture in the Apache Kafka
by 스뎅(thDeng) on
스뎅(thDeng) on
본 글은 아래 글을 발번역 한 내용입니다. 누락되거나 잘못 옮겨진 내용이 있을(
아니 많을;;) 수 있습니다. 어색하거나 잘못된 표현은 알려주세요.원글: Retrying consumer architecture in the Apache Kafka by Łukasz Kyć https://blog.pragmatists.com/retrying-consumer-architecture-in-the-apache-kafka-939ac4cb851a

이 글에서 Kafka 메시지를 처리할 때 만날 수 있는 문제의 종류를 설명하고 어떻게 해결할 수 있을지 설명하려 한다. 진행하기 앞서 Kafka 기본을 먼저 살펴볼 것을 추천한다.
Apache Kafka 기본
Apache Kafka는 유명한 분산 스트리밍 플랫폼 중 하나이다. 실시간 데이터 파이프라인에 사용되지만, 토픽의 영속성(저장) 때문에 이력 데이터 처리를 위한 메시지 스트림 저장소로도 사용될 수 있다. 확장성을 위해 Kafka 토픽은 하나 또는 여러 개의 파티션으로 구성된다. 내부적으로 하나의 파티션은 추가만 가능한(append-only) 한 개의 파일로 만들어 진다. 이런 간단한 데이터 구조를 사용하는 것은 상당히 높은 처리량(throughput)을 만들어 낸다. 이 내부 토픽 형식은 매우 중요한 의미를 가진다— 하나의 토픽 파티션으로부터 메시지를 하나씩 순차적인 순서대로만 컨슘할 수 있다.
아래 그림은 한 토픽 파티션의 순차적인 구조를 보여준다:
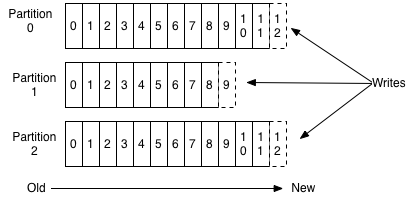
메시지 처리 문제
Kafka 토픽으로부터 메시지를 받아 메시지를 바로 처리하는 컨슈머의 구현은 매우 간단하다. 하지만 불행하게도, 현실은 훨씬 더 복잡하고 메시지 처리는 여러 이유로 실패할 수 있다. 이런 이유들 중 일부는 DB 정합성이라든가 잘못된 메시지 형식 같이 항상 발생하는 문제(permanent problem)이다. 또 다른 이유는 메시지를 처리하기 위해 사용하는 다른 시스템을 일시적으로 사용할 수 없는 것인데, 나중에 접속이 가능해 질 수 있다. 이런 문제는 메시지 처리를 다시 시도하는 것이 적당한 해결 방법일 것이다.
간단한 재시도 로직
아주 간단한 형태로는 고정된 딜레이로 계속 메시지 처리를 재시도할 수 있다. 이 컨슈머의 샘플 수도코드는 아래와 같다:
void consumeMainTopicWithSimpleRetry() {
while (true) {
boolean processedSuccessfully = true;
Message message = takeNextMessage("main_topic");
do {
try {
process(message);
} catch (Exception ex) {
waitSomeTime();
processedSuccessfully = false;
LOGGER.warn("Message processing failure. Will try once again.", ex);
}
} while (!processedSuccessfully);
}
}
넌블러킹(non-blocking) 재시도 로직
Kafka 같은 스트리밍 시스템에서는 메시지를 건너뛰고 나중에 다시 돌아올 수가 없다. Kafka에서 현재 메시지의 오프셋(offset)이라 부르는 포인터를 한번 움직이면, 다시 돌아갈 수가 없다. 간단하게 성공적으로 메시지를 처리한 직후에 컨슈머 오프셋이 바로 기억된다고 가정해 보자. 이런 오프셋을 되돌릴 수 없는 상황에서는 현재 메시지를 정상적으로 처리하지 않는 한 다음 메시지를 가져올 수 없다. 메시지 하나의 처리가 계속 실패하게 되면 시스템이 다음 메시지를 처리하지 못 하게 된다. 한 메시지의 처리 실패가 매번 다음 메시지의 처리 실패를 의미하는건 아니기 때문에 이런 상황을 피하고 싶은 것은 당연하다. 더욱이, 예를 들어 1시간 정도의 시간이 지나면 실패한 메시지들이 여러 이유로 성공할 수도 있다. 우리가 의존하는 시스템이 다시 동작하는 것이 그 이유 중 하나가 될 수 있다. 그렇다면 이런 단순한(naive) 구현을 어떻게 개선할 수 있을까?
메시지 처리에 실패하면 메시지의 복사본을 다른 토픽으로 전송하고 다음 메시지를 기다릴 수 있다. 이 새로운 토픽을 retry_topic이라고 부르자. retry_topic의 컨슈머는 Kafka로 부터 메시지를 받아온 다음 메시지 처리를 시작할 때 까지 미리 정해둔 시간(예: 1시간)을 기다릴 것이다. 이렇게 main_topic 컨슈머에는 아무 영향 없이 메시지 처리 시도를 미룰 수 있다. retry_topic 컨슈머의 처리가 실패하면,그 다음의 매뉴얼 처리를 위해 이 메시지 처리를 포기하고 failed_topic에 저장해야 한다. main_topic 컨슈머 코드는 다음과 같을 수 있다:
void consumeMainTopicWithPostponedRetry() {
while (true) {
Message message = takeNextMessage("main_topic");
try {
process(message);
} catch (Exception ex) {
publishTo("retry_topic");
LOGGER.warn("Message processing failure. Will try once again in the future.", ex);
}
}
}
그리고 retry_topic 컨슈머의 코드는 아래와 같다:
void consumeRetryTopic() {
while (true) {
Message message = takeNextMessage("retry_topic");
try {
process(message);
waitSomeLongerTime();
} catch (Exception ex) {
publishTo("failed_topic");
LOGGER.warn("Message processing failure. Will skip it.", ex);
}
}
}
유연한 넌블러킹(non-blocking) 재시도 로직
위에서 언급한 방법이 좋아 보이지만, 여전히 개선할 점이 있다. 의존하는 시스템이 우리 예상 보다 더 오래 다운될 수도 있다. 이 문제를 해결하기 위해 마지막으로 포기하기 전에 여러번 재시도할 필요가 있다. 재시도 로직으로 인해 외부 시스템이 넘치거나 CPU를 과다하게 사용하는 것을 피하기 위해, 이후 시도의 간격을 늘릴 필요가 있다. 로직을 개선해 보자!
다음의 재시도 전략을 원한다고 가정하자:
- 5분 마다 2번 재시도
- 다음 30분 마다 3번 재시도
- 다음 1시간 이후 1번 재시도
- 그런 다음 메시지는 건너 뛴다(skip)
예를 들어 ‘5분, 5분, 30분, 30분, 30분, 1시간’ 같은 재시도 시퀀스로 나타낼 수 있다. 시퀀스가 6개의 요소로 이루어져 있기 때문에 최대 6번의 재시도를 한다는 것을 뜻한다.
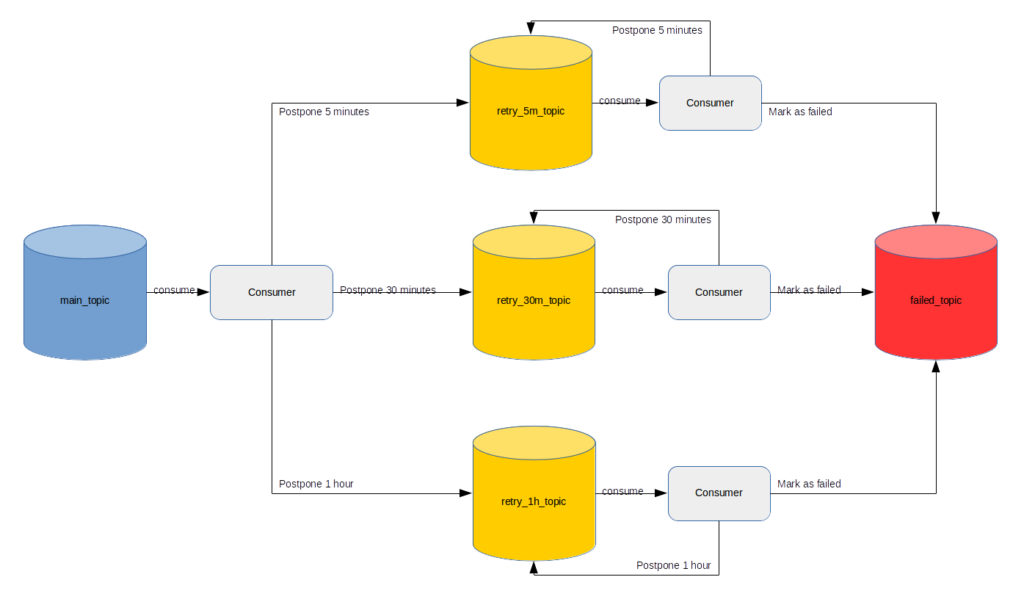
재시도 로직 처리를 위해 3개의 서로 다른 토픽을 만들고, 각각은 오직 하나의 딜레이 값을 가진다:
retry_5m_topic- 5분 후에 재시도retry_30m_topic- 30분 후에 재시도retry_1h_topic- 1시간 후에 재시도
메시지 라우팅 알고리즘은 위에서 봤던 방법과 매우 비슷하다. 딜레이 시간을 한가지에서 세가지로 확장하고 미리 설정한 재시도 횟수만큼 재시도하도록 한다.
이제 아래 시나리오를 고려해 보자. main_topic에 새로운 메시지 하나를 전송한다. 만일 이 메시지 처리가 실패하면, 재시도 시퀀스의 맨처음이 5분이기 때문에 5분 후에 다시 한 번 재시도를 해야 한다. 어떻게 하면 될까? 실패한 메시지와 다음 2개 필드를 넣은 새로운 메시지를 retry_5m_topic으로 전송한다.
retry_number: 1retry_timestamp: 현재 시각 + 5분
main_topic 컨슈머는 실패한 메시지 처리의 책임을 다른 구성요소에 위임한다는 뜻이다. main_topic 컨슈머는 블러킹되지 않고 다음 메시지를 꺼내올 수 있다. retry_5m_topic 컨슈머는 main_topic 컨슈머가 전송한 메시지를 즉시 받아 온다. 메시지에서 retry_timestamp 값을 읽고 그 때까지 스레드를 블러킹 시켜서 기다린다. 스레드가 깨어난 다음, 메시지를 처리하려고 다시 한 번 시도할 것이다. 성공하면 다음 메시지를 꺼내온다. 만약 실패하면 재시도 시퀀스가 6개로 되어 있고 지금 재시도가 처음이기 때문에 한 번 더 재시도할 것이다. 우리가 해야할 일은 메시지를 복사하고 attempt_number를 (여기서는 2) 증가시킨 다음 retry_timestamp를 (재시도 시퀀스의 두번째 값이 5분이기 때문에) 현재시각에 5분을 더하는 것이다. 복사된 메시지를 retry_5m_topic으로 다시 전송한다. 각 메시지 처리가 실패하면 각 메시지의 복사본이 retry_5m_topic이나 retry_30m_topic, retry_1h_topic 중 하나로 라우팅된다는 것을 알 수 있다. 가장 중요한 것은 한 토픽 내의 메시지들이 서로 다른 딜레이 값으로 계산된 retry_timestamp 속성으로 인해 순서가 섞이는 일이 없도록 하는 것이다.
재시도 시퀀스의 마지막에 다다르면 마지막 시도라는 뜻이다. 이제 “그만”이라고 외칠 때가 됐다. 메시지를 failed_topic으로 전송하고, 더 이상 처리하지 않는다. 메시지를 누군가가 매뉴얼로 처리하거나 그냥 버리면 된다.
아래 그림이 메시지 흐름을 이해하는데 도움이 될 것이다:
결론
지금까지 살펴보았듯이, 실패를 대비해 메시지 처리 지연을 구현하는 것은 하찮은 것이 아니다. 다음 내용을 명심하자:
- 토픽 파티션의 메시지는 순서대로만 컨슘할 수 있다.
- 메시지를 건너뛰거나 나중에 그 메시지로 다시 돌아올 수 없다.
- 일부 메시지 처리를 미루고 싶다면, 각 딜레이 값을 가진 별도의 토픽에 재전송할 수 있다.
- 메시지를 복사하고 재시도 횟수와 다음 재시도 타임스탬프 정보를 넣어서 재시도 토픽으로 재전송함으로써 실패한 메시지를 처리할 수 있다.
- 재시도 토픽의 컨슈머는 메시지를 처리할 때가 될 때 까지 스레드가 블러킹 되도록 해야 한다.
- 재시도 토픽에 있는 메시지는
retry_timestamp필드 순으로 정렬되어서 자연적으로 시간순으로 구성된다.
