[CSV] Mac, 리눅스 등에서 만든 CSV 파일이 윈도에서 깨질 때
by 스뎅(thDeng) on
스뎅(thDeng) on
문제
CSV 파일을 개발용 Mac이나 리눅스 또는 같은 OS의 서버에서 만들었을 때, UTF8로 저장하면 윈도에서 열면 깨지는 경우가 있다.

CSV 저장하는데 큰 기술적인 도전(?)이 필요한 것이 아니라 저장에는 문제가 없다 생각이 들었고, 정말 그냥 설마하는 마음으로 BOM(Byte Order Mark) 캐릭터가 떠올랐다.
그리고 그게 진짜 답이었다. (야호!! 소 뒷걸음질 성공!!)
해결방법
CSV 파일 맨 앞에 BOM 캐릭터를 추가한다. (Java 코드)
BufferedWriter bw = ..;
bw.write("\ufeff");
bw.write(0xFEFF);
StringBuffer sb = ..;
sb.append(0xFEFF);
sb.append(new Char(0xFEFF));
저장된 BOM 캐릭터
재밌게도 BOM 캐릭터는 FE FF인데, 실제로 저장된 값은 EF BB BF가 된다. (참고: Why UTF-8 BOM bytes efbbbf can be replaced by \ufeff?)
UTF8은 문자 저장에 7비트를 사용하고, 이것이 넘쳐서 FE FF를 저장하기 위해 3바이트를 사용하게 된다. 아래는 Stack overflow 내용 일부 발췌.
For the BOM we need three bytes.
hex FE FF
binary 11111110 11111111
encode the bits in UTF-8
pattern for three byte encoding 1110 xxxx 10xx xxxx 10xx xxxx
the bits of the code point 1111 11 1011 11 1111
result 1110 1111 1011 1011 1011 1111
in hex EF BB BF
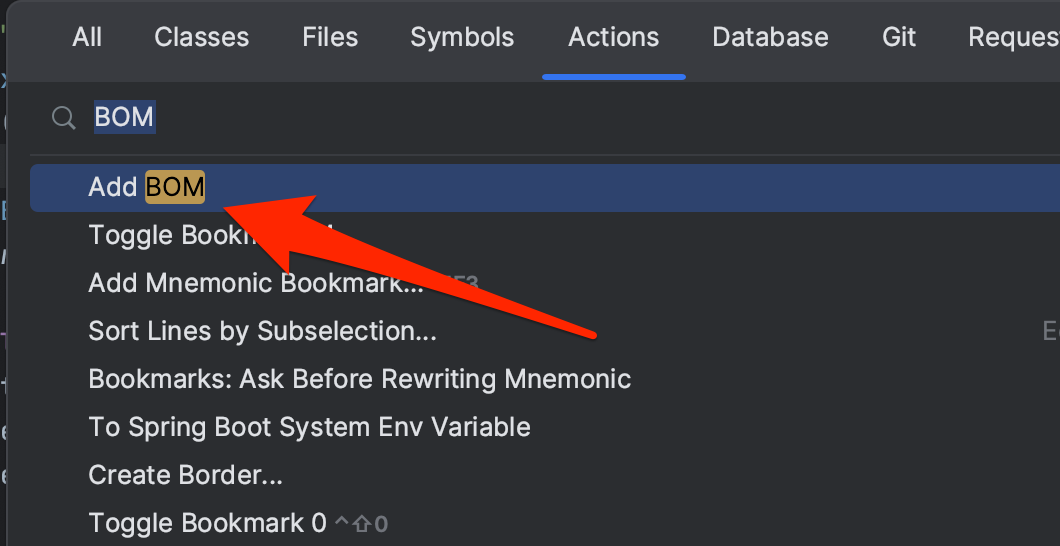
IntelliJ 팁
IntelliJ에는 파일에 BOM 캐릭터를 쉽게 넣거나 뺄 수 있는 기능이 있다.
Shift를 두번 누르고 BOM을 검색하면, Add BOM 메뉴를 찾을 수 있다. 이것이 보이면 BOM 캐릭터가 없는 것이고, Remove BOM이 보이면 이미 BOM 캐릭터가 붙어 있는 것이다.