[Data] Precision(정확률)과 Recall(재현률)
by 스뎅(thDeng) on
스뎅(thDeng) on
이전 블로그에서 옮겨온 포스트
After finishing a search the nagging question in every searcher’s mind is: “Have I found the most relevant material or am I missing important items?” In addition every searcher hopes they don’t retrieve “a lot of junk”. Unfortunately getting “everything” while avoiding “junk” is difficult, if not impossible, to accomplish. However, it is possible to measure how well a search performed with respect to these two parameters.
Precision (정확률) / Recall (재현률)
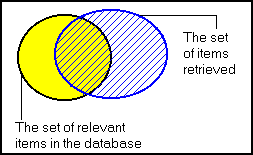
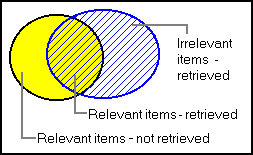
Precision and recall are the basic measures used in evaluating search strategies. As shown in the first two figures on the left, these measures assume:
- There is a set of records in the database which is relevant to the search topic
- Records are assumed to be either relevant or irrelevant (these measures do not allow for degrees of relevancy).
- The actual retrieval set may not perfectly match the set of relevant records.
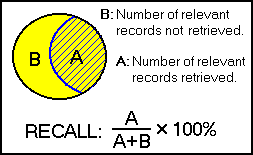
RECALL is the ratio of the number of relevant records retrieved to the total number of relevant records in the database. It is usually expressed as a percentage.
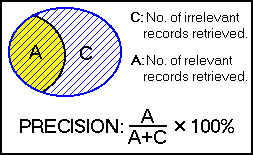
PRECISION is the ratio of the number of relevant records retrieved to the total number of irrelevant and relevant records retrieved. It is usually expressed as a percentage.
한마디로 RECALL 은 추천 가능한 (추천했을 때 욕 안 먹는) 아이템 중에 얼마나 추천해주었는가?? PRECISION 은 추천해준 것 중 제대로 추천해준 것이 얼마나 되는가?? 정도?? ㅋㅋ 또 다른 말로는 PRECISION 은 얼마나 정확하게 추천해주는가(믿을만한가)?? 원하지 않는 것을 얼마나 잘 제거했는가?? RECALL 은 이 추천 시스템이 추천 가능한 아이템을 얼마나 커버(재현)할 수 있는가?? 원하는 것을 얼마나 잘 추천하는가?? (역시 장담은 못 한다) 정도?? ㅋㅋ (원문은 검색의 예로 설명을 했고, 나는 추천을 예로 설명을…-ㅅ-;)
Precision과 Recall은 반비례 관계
그런데 이들은 일반적으로 반비례 관계에 있다고 한다. 극단적인 예로, relevant 아이템을 모두 추천(검색)하면 recall이 100%가 되고, 반대로 relevant 아이템 하나만을 추천(검색)한다면 precision이 100%가 된다.
일반적으로 recall 이 높으면 precision이 낮고, recall이 낮으면 precision이 높다고 한다. 어디까지나 일반적인 것이다.
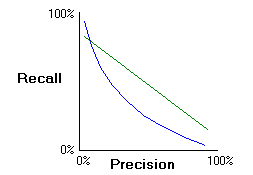
두 그래프는 서로 다른 검색 엔진이나 추천 시스템을 사용했을 때의 차이가 있을 수 있음을 보여주는 것이다. precision과 recall 중 어떤 것이 더 중요한지는 시스템의 특성에 따라 다르기 때문에 시스템에 따라서 중요도가 달라질 수 있다. 검색의 경우는 사용자들이 검색된 내용의 상위 몇 개만을 보려고 하기 때문에 precision이 매우 높아야 한다.
문제점
Precision과 Recall을 사용하기 위해서는 테스트 아이템이 relevant한지 irrelevant한지를 미리 알고 있어야 한다. 하지만, 어떤 테스트 아이템은 relevant와 irrelevant 중간에 있을 수도 있고, 어떤 테스트 아이템은 어떤 사람한테는 relevant하고 다른 사람한테는 irrelevant할 수도 있다.
또한 Recall을 계산하기 위해서는 DB에 있는 많은 relevant 아이템을 모두 알고 있어야 한다는 단점도 있다. 모든 relevant 아이템을 알고 있다면 추천(검색)을 할 필요가 있을까?? ^^ 이를 찾기 위해 다른 추천(검색)으로 추천(검색)된 relevant 아이템을 relevant 아이템으로 간주하는 방법도 있고(샘플링, sampling), 여러 시스템에서 relevant 아이템이라고 판단하는 아이템들을 좋은 relevant 아이템으로 간주하는 방법(풀링, pooling)도 있다.
